AWS 클라우드환경 네이티브 수업 77일차
진행
1. Create / Insert / Delete / Update / Alter (Drop)
곱집합, 합집합 (Union) ( 8/30 Cartesian Product , 9/5 DML 및 합집합 참고)
2. 집합 연산자
(교집합 (INTERSECT), 차집합 (MINUS), 대칭 차집합 (Symmetric Difference ))
3. VIEW
오늘은 Zoooooooooooooooooooooooooommmmmm~~~
요약
1. 집합 연산자
(교집합 (Intersect), 차집합 (Minus), 대칭 차집합 (Symmetric Difference ))
2. VIEW
(View의 필요성, View의 생성/ 수정/ 삭제, View의 종류와 데이터 업데이트 )
집합 연산자
두 개의 테이블을 집합으로 봤을 때,
두 집합을 이용해 1개짜리 다양한 결과로 내고자 하는 연산자 이다
집합 개념 자체는 수학 때 배운 개념과 똑같다.
곱집합(Cartesian Product), 합집합(Union),
교집합 (Intersect), 차집합 (Minus), 대칭 차집합 (Symmetric Difference)이 있고
곱, 합집합은 이 페이지 상단에 설명 페이지를 첨부해두었다.
위에 있는 그 외의 집합을 각각의 예를 보면서 이해를 해보려 한다.
먼저 아래와 같이 테이블 A, B를 만들고 그 안에 데이터를 넣어보자.
A는 1~8까지 / B는 홀수 데이터만 들어있다.
-- 테이블 생성
CREATE TABLE tableA (
-- UNSIGNED (부호 없이 양수만 쓰겠다)
NO INT(10) UNSIGNED NOT NULL AUTO_INCREMENT,
ID VARCHAR(20) NOT NULL DEFAULT '',
NAME VARCHAR(20) NOT NULL DEFAULT '',
PRIMARY KEY (NO)
) ENGINE=InnoDB DEFAULT CHARSET=UTF8 AUTO_INCREMENT=1;
CREATE TABLE tableB (
NO INT(10) UNSIGNED NOT NULL AUTO_INCREMENT,
ID VARCHAR(20) NOT NULL DEFAULT '',
NAME VARCHAR(20) NOT NULL DEFAULT '',
PRIMARY KEY (NO)
) ENGINE=InnoDB DEFAULT CHARSET=UTF8 AUTO_INCREMENT=1;
-- 데이터 입력
INSERT INTO tableA VALUES (1, '101', 'Value 101');
INSERT INTO tableA VALUES (2, '102', 'Value 102');
INSERT INTO tableA VALUES (3, '103', 'Value 103');
INSERT INTO tableA VALUES (4, '104', 'Value 104');
INSERT INTO tableA VALUES (5, '105', 'Value 105');
INSERT INTO tableA VALUES (6, '106', 'Value 106');
INSERT INTO tableA VALUES (7, '107', 'Value 107');
INSERT INTO tableA VALUES (8, '108', 'Value 108');
INSERT INTO tableB VALUES (1, '101', 'Value 101');
INSERT INTO tableB VALUES (3, '103', 'Value 103');
INSERT INTO tableB VALUES (5, '105', 'Value 105');
INSERT INTO tableB VALUES (7, '107', 'Value 107');
INSERT INTO tableB VALUES (9, '109', 'Value 109');


1. 교집합 (Intersect)
A와 B의 공통된 데이터 (1, 3, 5, 7) 만 뽑아낸다.
Join 방법 별로 방식은 아래와 같다.
(Join - Left Join - Right Join 순)
SELECT a.ID, a.NAME 'A', b.NAME 'B'
FROM TABLEA a JOIN TABLEB b
ON a.ID = b.ID;
SELECT a.ID, a.NAME 'A', b.NAME 'B'
FROM TABLEA a LEFT JOIN TABLEB b
ON a.ID = b.ID
WHERE b.ID IS NOT NULL;
SELECT a.ID, a.NAME 'A', b.NAME 'B'
FROM TABLEA a RIGHT JOIN TABLEB b
ON a.ID = b.ID
WHERE a.ID IS NOT NULL;

2. 차집합 (Minus)
한 쪽 테이블에서 한 쪽 테이블을 뺀다.
아래는 A - B / B - A 의 방식 및 결과다.
A - B
SELECT a.ID, a.NAME 'A'
FROM TABLEA a
WHERE a.ID NOT IN ( SELECT b.ID
FROM TABLEB b);
SELECT a.ID, a.NAME 'A'
FROM TABLEA a
WHERE NOT EXISTS ( SELECT 1
FROM TABLEB b
WHERE a.ID = b.ID);
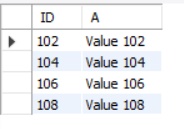
B - A
SELECT b.ID, b.NAME 'B'
FROM TABLEA a RIGHT JOIN TABLEB b
ON a.ID = b.ID
WHERE a.ID IS NULL;
SELECT b.ID, b.NAME 'B'
FROM TABLEB b
WHERE b.ID NOT IN ( SELECT a.ID
FROM TABLEA a);
SELECT b.ID, b.NAME 'B'
FROM TABLEB b
WHERE NOT EXISTS ( SELECT 1
FROM TABLEA a
WHERE a.ID = b.ID);

3. 대칭 차집합 (Symmetric Difference )
두 집합의 합에서 교집합을 뺀 부분을 말한다.
고로 (A U B) - (A ∩ B) 가 되도록 쿼리를 짜면 된다.
아래를 보자.
SELECT T.ID, T.NAME
FROM ( SELECT ID, NAME FROM TABLEA
UNION
SELECT ID, NAME FROM TABLEB) T
WHERE T.ID NOT IN ( SELECT a.ID
FROM TABLEA a JOIN TABLEB b
WHERE a.ID = b.ID);
SELECT T.ID, T.NAME
FROM ( SELECT ID, NAME FROM TABLEA
UNION ALL
SELECT ID, NAME FROM TABLEB) T
GROUP BY T.ID, T.NAME
HAVING COUNT(T.ID) = 1;

VIEW
- 하나 이상의 기본 테이블 / 다른 뷰를 이용하여 쿼리문으로 생성하는 가상 테이블
- 기본 테이블은 디스크에 공간이 할당되어 데이터를 저장,
반면에 뷰는 데이터 딕셔너리 (Data Dictionary) 테이블에 뷰에 대한 정의 (SQL 문) 만 저장되어
디스크 저장 공간 할당이 이루어지지 않음
- 실제 데이터가 없는 가짜지만, 테이블과 같은 자격을 가진다. (즉, 테이블 위치에 다 들어갈 수 있다.)
- 전체 데이터 중에서 일부 필드나 일부 행만 필요할 때 사용
- 원본 테이블이 내용이 바뀌면 뷰도 같이 바뀌고, 원본을 삭제하면 뷰는 작동하지 않음.
- 반대로, 뷰의 내용을 수정하면 원본 테이블의 내용도 변한다.
- 뷰로 다른 뷰를 만들 수도 있다.
View가 필요한 이유
- 사용자 별로 특정 데이터만 조회할 수 있도록 할 필요가 있음
(보안이 필요할 수 있는 정보에 접근을 제한하기 위해)
- 복잡한 쿼리문 단순화
- 데이터의 중복성을 최소화
(예를 들어 전체 테이블에서 추가로 다른 테이블로 만들면 데이터의 중복성이 발생함)
View의 생성/ 수정/ 삭제
View는 생성과 삭제, 그리고 수정이 자유롭다.
수정의 경우, 똑같은 이름의 View의 내용을 바꾸고 싶을 때 굳이 삭제 하지 않고 바로 수정하기 위해 사용한다.
만약 해당 이름의 View 가 없다면 새로 생성한다.
구조는 아래와 같다.
1. View 생성
Create View 뷰이름 As Select문;
CREATE VIEW v_emp1 AS
SELECT first_name, last_name, email, hire_date
FROM employees;
2. View 수정
Create Or Replace View 뷰이름 As Select문;
create or replace view v_emp1 as
SELECT last_name, first_name, hire_date
FROM employees;
3. View 삭제
Drop View 뷰이름 ;
Drop View v_emp1;
View의 종류와 데이터 업데이트
우선, View 종류에는 2가지가 있다.
- 단순 View : 하나의 테이블에 파생되어 정의된 뷰
- 복합 View : 두개 이상의 테이블로부터 파생되어 정의된 뷰 (Join을 사용한 View)
View는 기본적으로 기본 테이블과는 다르게
DML(SELECT , INSERT , UPDATE , DELETE)의 제약이 있다.
또한, 그것이 단순View냐 복합View냐에 따라 제약 범위가 다르다.
지금부터 데이터 업데이트에 대해 알아보도록 하자.
1. 단순 View의 데이터 업데이트
View를 업데이트를 하면 기본적으로 원본 테이블의 데이터도 업데이트가 된다.
아래의 예를 보자,
-- employees 테이블 기반 뷰 생성
CREATE OR REPLACE VIEW v_emp1_update AS
SELECT first_name, last_name, email, hire_date
FROM employees
WHERE department_id IN (20, 30);
-- 뷰 업데이트
UPDATE v_emp1_update
SET last_name = '길동'
WHERE first_name = 'Michael';


위에서는 Update를 이용해 데이터를 수정을 했다.
이번에는 Insert를 이용해 데이터를 추가를 해보자.
1. ERROR
INSERT INTO v_emp1_update
VALUES ('Killdong', 'Hong', 'HKD', now());
2. 제대로 적었지만 ERROR
INSERT INTO v_emp1_update
VALUES (9998, 'Killdong', 'Hong', 'HKD', now(), 'IT_PROG', 40, 5000);
1번 : 뷰의 레코드 필드수와 실제 테이블의 레코드값에 들어갈 필드의 수가 다르기 때문에 에러가 난다.
2번 : 1번을 수정하여 필드 수에 맞게 데이터를 넣었는데도 에러가 난다.
그 이유는 View를 통해서 넣으려는 Values의 값과 원본 테이블에 매칭되는 필드가 잘못되었기 때문
원본 테이블은 employee_id, first_name, last_name, email, phone_number, hire_date, job_id, salary ...순의 테이블.
View는 first_name, last_name, email, hire_date 순의 테이블이다.
여기서 원본 테이블의 employee_id는 Primary Key 이므로 필수로 들어가줘야한다.
따라서, 아래와 같이 View 의 필드 순서를 변경을 하고 데이터 추가를 해야 에러가 발생하지 않는다.
1. View 내용 변경
CREATE OR REPLACE VIEW v_emp1_update AS
SELECT employee_id, first_name, last_name, email, hire_date, job_id, department_id, salary
FROM employees
WHERE department_id IN (20, 30);
2. View에서 데이터 추가
INSERT INTO v_emp1_update
VALUES (9999, 'Killdong', 'Hong', 'HKD', now(), 'IT_PROG', 20, 5000);
3. 데이터 추가가 가능하나 View에는 보이지 않음
INSERT INTO v_emp1_update
VALUES (9998, 'Killdong', 'Hong', 'HKD', now(), 'IT_PROG', 40, 5000);


3번 : 9998를 추가했으나 테이블에서는 보이지만 뷰에서는 보이지 않는다.
뷰의 조건이 department_id가 20이나 30인것만 보이므로 뷰에서는 안보이는 것.
하지만, 뷰의 조건에 맞지 않아도 뷰에서 원본 테이블로 데이터를 추가하는건 가능하다.
데이터의 삭제는 아래의 쿼리를 보면서 이해하면 된다.
뷰에서 보이는 데이터는 1번처럼 뷰에서 삭제가 가능하지만
뷰에서 보이지 않는 데이터는 2번처럼 테이블에서 삭제를 해야한다.
1. 뷰에서 데이터 삭제
DELETE FROM v_emp1_update WHERE employee_id = 9999;
2. 테이블에서 삭제
DELETE FROM employees WHERE employee_id = 9998;
이처럼 귀찮은 작업을 하지 않으려면 보이지 않는 데이터를 생성 못하게 하면 된다.
WITH CHECK OPTION를 사용하면 보이지 않는 데이터 생성 시 ERROR가 발생하게 할 수 있다.
CREATE OR REPLACE VIEW v_emp1_update AS
SELECT employee_id, first_name, last_name, email, hire_date,
job_id, department_id, salary
FROM employees
WHERE department_id IN (20, 30)
WITH CHECK OPTION; -- 에러 발생
2. 복합 View의 데이터 업데이트
우선, 복합 View에서의 데이터 삭제는 불가능하다.
복합 View에서 업데이트는 아래와 같다.
View에서 업데이트 한 데이터는 두 개의 테이블 중 Primary Key를 가진 필드에
업데이트한 데이터가 들어가게 되면 해당 테이블로 들어간다.
아래의 경우, emp의 Primary 필드인 employee_id에는 데이터가 들어가고
departments의 Primary 필드인 department_id에는 데이터가 들어가지 않아서
emp에 데이터가 추가된 모습을 볼 수 있다.
1. employees, departments 테이블의 Join View
CREATE OR REPLACE VIEW v_emp1_dual_update AS
SELECT emp.employee_id, emp.first_name, emp.last_name, emp.email,
emp.hire_date, emp.job_id, emp.department_id 'emp_department',
dep.department_id 'dep_department', dep.department_name, salary
FROM employees emp, departments dep
WHERE emp.department_id = dep.department_id
AND dep.department_id IN (20, 30);
2. 데이터 추가
INSERT INTO v_emp1_dual_update
(employee_id, first_name, last_name, email, hire_date, job_id, emp_department, salary)
VALUES (8888, '청이', '심', 'STK', now(), 'FI_MGR', '30', 6666);





댓글